Angel Mansilla

WebScraping and Analysing Data on QuintoAndar
PARTE 1
Web Scraping e Data Cleaning em Python
1 - Contexto de Negócio
Roberto, um corretor de imóveis, decide se mudar para o Rio de Janeiro em busca de melhores oportunidades de trabalho, porém, ele percebe que as características, valores e itens que os imóveis possuem são diferentes dos que ele está acostumado, gerando problemas na efetividade de seu serviço.
Então, ele encontrou uma possível solução para seu problema, Roberto decidiu realizar uma análise de dados no site da empresa "QuintoAndar", uma das principais plataformas de venda e aluguel de imóveis, que possui informações detalhadas sobre valores, interiores dos imóveis, além de outras coisas.
2 - Extração de Dados
Primeiramente, busquei uma API para realizar a coleta dos dados, entretanto, encontrei que a maioria dos sites semelhantes ao QuintoAndar, ou não possuem uma API, ou as que possuem não permitem muitas consultas para usuários gratuitos, por isso, optei por realizar Web Scraping com Python, usando das bibliotecas BeautifulSoup4 e Selenium para isso.

Mesmo que inicialmente esse projeto tenha sido visado para utilizar apenas o BS4, fez-se necessário a utilização do Selenium, visto a dinamicidade do site, graças a utilização de JavaScript, que o BS4 não consegue lidar muito bem. Na imagem acima, constam todas as importações feitas desse projeto.
3 - WebScraping em Python
O processo para extrair o conteúdo do site era simples, mas complexo, existiam links escondidos nas imagens que redirecionavam para outro site com conteúdo completo do imóvel, para isso, programei o Selenium para atravessar o site e clicar no "Ver mais", por uma quantidade opcional de vezes, e então, que extraísse todo o HTML do site, onde estão todos os links, para que tal conteúdo fosse utilizado pelo BeautifulSoup4.
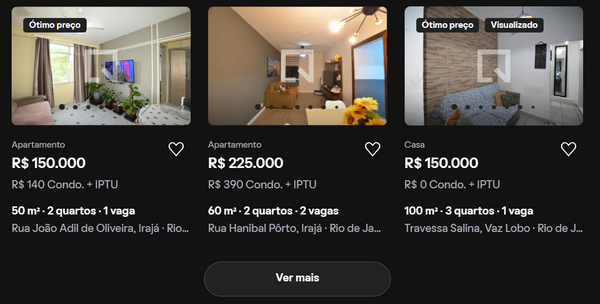
Com todo o HTML recebido, ele foi passado como parâmetro para a função extrair_links, que copiava todos links escondidos nas imagens, baseado em um padrão que identifiquei, e então, adicionava todos esses links através de uma list comprehension, e retornasse ao usuário essa mesma lista de links.

Nesses links, estão contidas diversas informações sobre o imóvel, como preço, número de quartos, IPTU, dentre outros, e com a lista de links pronta, eu criei diversas funções para extrair e limpar esses conteúdos, exemplo: remover R$ dos preços, mas por serem muitas, cerca de onze no total, apenas irei relatar a primeira delas, que extrai a identificação dos imóveis, que servirá de primary_key futuramente.
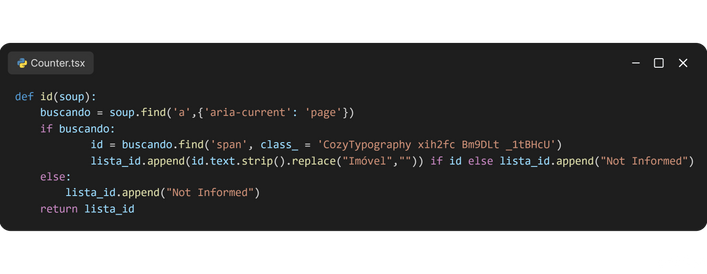
Essa função possui duas funções, a primeira sendo localizar o elemento ID em um link fornecido, garantindo que mesmo que não seja encontrado, o ID receba a string: "Not Informed", evitando truncamentos, já a segunda é limpar as ID´s encontradas de sua parte de texto "Imóvel", permitindo que tornem-se inteiros, isso foi feito com o uso da função replace do Python, após isso, todos os elementos são adicionados na última posição da lista_id.
Com isso, as principais informações foram extraídas dos sites e colocadas em listas, que foram agrupadas em 4 datasets de categorias semelhantes, que serão concatenados com outros 8 datasets com as mesmas colunas, mas com linhas que referenciam a outros estados do sudeste, mais informações sobre o escopo dos dados futuramente.

Repetindo uma última vez, informações completas sobre o funcionamento desse código, de sua lógica, limpeza e funções está disponível em um notebook Jupyter em meu GITHUB, presente no cabeçalho desta página ao lado do LinkedIn.
4 - Carregamento dos Dados
Com o WebScraping concluído, os dados foram colocados em arquivos CSV, e estão prontos para serem carregados à database do MySQL, logicamente tive de criar as quatro tables antes, todas criadas nas especificações dadas no Dicionário de Dados, e então utilizei o LOAD DATA LOCAL INFILE para adicionar os arquivos nessas tables, tal como aprendi no último projeto.

5 - Dicionário de Dados
Tabela 1: Descrição do Imóvel
-
ID: Identificador único do imóvel (inteiro).
-
Tipo: Tipo de imóvel (string).
-
Descrição: Descrição detalhada do imóvel (string).
-
Bairro: Bairro onde o imóvel está localizado (string).
-
Logradouro: Endereço completo do imóvel (string).
-
Publicação(Dias): Número de dias desde a publicação do anúncio (inteiro).
Tabela 2: Informações de Custos do Imóvel
-
ID: Identificador único do imóvel (inteiro).
-
Preço: Preço do imóvel (float).
-
Condomínio: Valor do condomínio associado ao imóvel (float).
-
IPTU: Valor do Imposto Predial e Territorial Urbano (IPTU) mensal (float).
Tabela 3: Especificações Internas do Imóvel
-
ID: Identificador único do imóvel (inteiro).
-
Quartos: Número de quartos no imóvel (inteiro).
-
Área: Área total do imóvel em metros quadrados (float).
-
Proximidade com Metrô: Indica se o imóvel está próximo de um metrô (string).
-
Vagas: Número de vagas de estacionamento disponíveis (inteiro).
-
Banheiros: Número de banheiros no imóvel (inteiro).
-
Andares: Indica entre quais andares se localiza o imóvel (string).
-
Mobiliagem: Indicação se o imóvel é mobiliado.(string)
Tabela 4: Expansão dos Itens do Imóvel
-
ID: Identificador único do imóvel (inteiro).
-
Item: Itens presentes no imóvel, explosão da "Descrição" (string).
6 - Diagrama de Relacionamento de Entidades

7 - Escopo de Dados e Informações Adicionais
Finalmente, com todos os dados carregados no MySQL, a análise pode começar, e nessa seção final da Parte 1, irei demarcar alguns pontos interessantes sobre o escopo dos dados, eu adoraria ter um conjunto maior com informações sobre todo o Brasil e mais imóveis, mas por conta de limitações do site sobre as regiões e também desempenho no PC, essa foi quantidade maior que consegui extrair, ainda assim, de certo conseguirei extrair bons insights sobre a região!
Linhas
8250 linhas de imóveis, sendo 2950 para cada estado
Período de Coleta
Dados abrangendo
do ano de 2023-2024
Colunas
16 colunas distintas entre as 4 tables
Agradecimento
Usuários do Reddit BrDev, Dados Brasil e Stack, muito obrigado!
Região de Coleta
Capitais dos estados do sudeste brasileiro
